Why is Random Forest better than Decision Trees?

Search for a command to run...
Insightful and clean!
Thank you!
1. Introduction In 2017, Vaswani et al. dropped a paper titled “Attention Is All You Need,” and it quietly rewired the entire field of deep learning. Within a few years, its architecture — the Transformer — became the foundation for nearly every mode...

Introduction What happens when you need to store the entire web? That’s the kind of problem Google faced in the early 2000s, and the solution they came up with was the Google File System (GFS). Today I read through the GFS paper — my first real syste...

Introduction When I started working with Oracle SQL, my relationship with databases was simple: they stored my data, and I fetched it when I needed it. SELECT, INSERT, UPDATE, DELETE—that was my comfort zone. Anything beyond that felt like DBA territ...

What started as a simple project to learn GitHub Actions became a potentially powerful conduit for collaboration. NewsCom envisages diverse voices to converge to share insights, experiences, and stories. In this blog, we embark on a journey through a...

Step 1: Organize Files Place your HTML file, CSS file, and assets/js in a dedicated folder. Let's call it website. The folder structure should look something like this. ├── .github/workflows/deploy.yml # we'll talk about this later ├── /W...

Ok, so let us consider the Dataset given below.
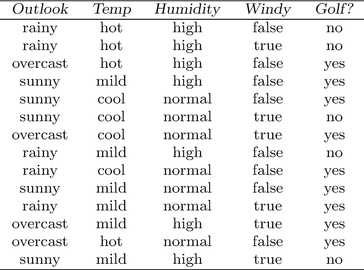
A Decision Tree fitting this dataset would look like something like this.
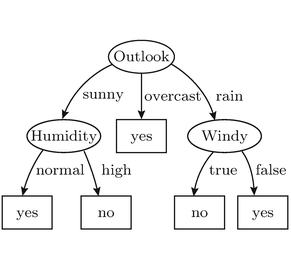
All good, right? But what if we encounter a change in the original data set? Would the Decision Tree still work as expected? Would it still generalize well to the changed Dataset and continue producing results in accordance with its earlier accuracy?
The answer is No.
Let's see by changing the original dataset.
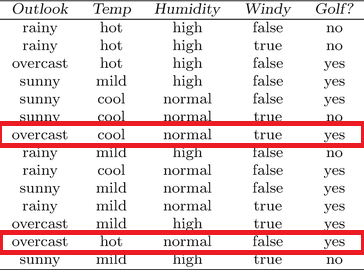
If we just change these two entries to no instead of yes. The Decision tree would have a 50% chance of predicting the correct result. And this is just in the Training Set. We can safely say that any change in the original Data reflects hugely on the performance of the Decision Tree generalized on the unchanged Data. So what do we do?
We used an ensemble technique called Random Forest.
What is an ensemble technique in Machine Learning?
Ensemble methods is a machine learning technique that combines several base models in order to produce one optimal predictive model. Meaning Apes Together Strong.
So, what actually happens in a Random Forest? Let's see.
Bootstrapping
Random Feature Selection
Simultaneous Model Training
Aggregation
We take rows from the dataset with replacement. We take as many rows as were present in the original dataset. This means that there may be repetitions in the new bootstrapped dataset. We make a number of these new datasets (a hyperparameter).
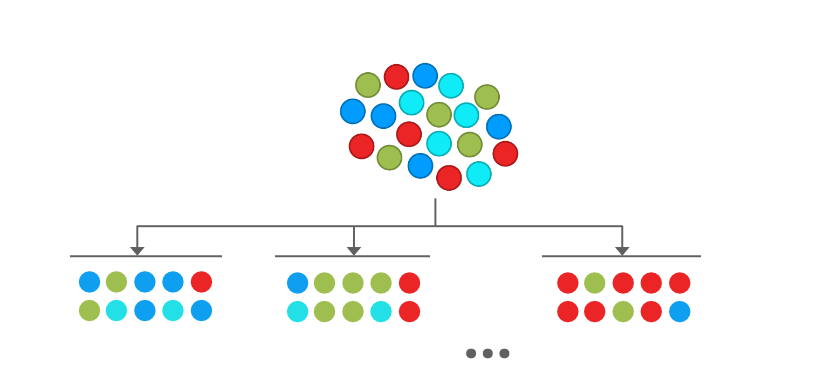
Notice that in the picture above, There are (maybe) repetitions in each bootstrapped dataset.
We randomly select a few (another hyperparameter) columns (features) for each dataset.
For example First two features for the first dataset, the Last two for the second...
At this point, we have various individual Datasets. What to do next? Train a Decision Tree model on each of those.
Build Trees for all datasets. This brings along all the hyperparameters associated with each Decision Tree.
We now have completed all the parts in Random Forest. The next question is...
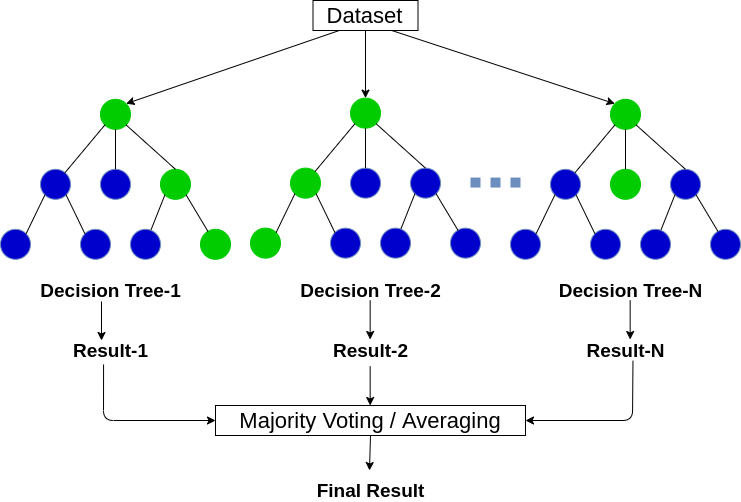
Simple! The steps are
Bootstrap rows
Select Random Features
Train Decision Trees on each
Make predictions using all models. For Classification take the majority vote and for Regression take an average or weighted average or mode (whatever gives the best result).
Ans. Due to Bootstrapping and Random Feature Selection which randomizes the datasets.
Ans. Because there are more than 1 Decision Trees. Trees. Get it? :D
Ans. Bootstrap ensures that we don't use the same data every time. So our model(s) is(are) less sensitive to the original dataset. Random Feature Selection on the other hand reduces the correlation between trees. If Random Feature Selection was not used all trees would produce very similar results and increase overall variance. Some trees would give bad results and others bad results in the opposite way thus balancing it out.
Ans. 2 values usually give the best result
Log of the total number of features.
Square root of the total number of features
High variance of Decision tree averages out to be low variance because
Each tree recognizes a few features.
We take majority or mean.
Cheers!