Web Basics - Part 3

Basic Architecture of the Web
The basic architecture of the web is a distributed client-server architecture, where the client sends requests to a server and the server sends responses back to the client. The client is typically a web browser or other application that requests information or services from a server. The server is a computer program or machine that provides the requested information or services to the client.
The client-server architecture is built on top of the TCP/IP protocol stack, which consists of a set of protocols that define how computers communicate over a network. At the application layer, the most commonly used protocols in the client-server architecture are HTTP (HyperText Transfer Protocol), FTP (File Transfer Protocol), SMTP (Simple Mail Transfer Protocol), and DNS (Domain Name System).
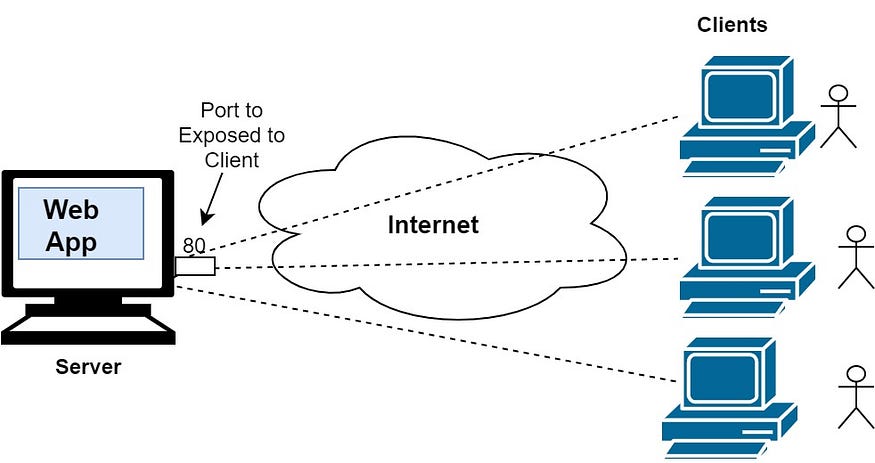
HTTP is the protocol that defines how web pages are transferred between clients and servers. It is a request-response protocol, where the client sends a request to the server and the server sends a response back to the client. FTP is the protocol that defines how files are transferred between clients and servers. SMTP is the protocol that defines how email messages are transferred between clients and servers.
Role and Anatomy of IP Addresses
An IP address is a unique numerical identifier that is assigned to devices connected to the internet. It stands for Internet Protocol address and is used to route data packets from one device to another.
There are two types of IP addresses: IPv4 and IPv6. IPv4 is a 32-bit address and can support up to 4.3 billion unique addresses. IPv6, on the other hand, is a 128-bit address and can support significantly more unique addresses. IPv6 was developed to address the shortage of IPv4 addresses.
IP addresses are used to identify devices on the internet. When a device connects to the internet, it is assigned an IP address. This IP address is used to route data packets from one device to another. When you enter a website's domain name into your browser, the browser uses DNS to translate that domain name into an IP address. The IP address is then used to establish a connection between your device and the website's server, allowing data to be transmitted back and forth.
An IP address consists of two parts: the network address and the host address. The network address is used to identify the network that the device belongs to, while the host address identifies the specific device on that network. The division between the network address and host address is determined by the subnet mask.
In IPv4, the first few bits of the address represent the network address, while the remaining bits represent the host address. The subnet mask is used to determine the number of bits used for the network address and the host address. For example, a subnet mask of 255.255.255.0 indicates that the first three octets of the IP address represent the network address, and the last octet represents the host address.
In IPv6, the first 64 bits of the address represent the network address, while the remaining 64 bits represent the host address. The division between the network address and host address is fixed and determined by the structure of the IPv6 address.
In summary, IP addresses are a crucial component of the internet as they allow devices to communicate with each other. They are used to identify devices on the internet and route data packets from one device to another.
How does DNS work?
DNS (Domain Name System) is a hierarchical system that translates domain names into IP (Internet Protocol) addresses and vice versa.
When a user types a domain name in their web browser, the computer sends a request to a DNS resolver to resolve the domain name into an IP address. The resolver first checks its cache to see if it has a record of the IP address for the domain name. If the resolver does not have a record, it sends a query to the root DNS server, which response with a referral to the appropriate Top-Level Domain (TLD) DNS server for that domain.
The TLD DNS server then responds with a referral to the authoritative DNS server for the domain, which has the IP address information for the domain. The resolver then caches the IP address information and returns it to the user's computer, allowing the web browser to connect to the IP address and load the website associated with the domain name.
Conversely, when a user enters an IP address in their web browser, the DNS resolver performs a reverse DNS lookup to translate the IP address into a domain name. The process is similar to the forward DNS lookup, but it involves querying different DNS servers and databases to find the domain name associated with the IP address.
Overall, the DNS system is crucial for navigating the internet and accessing websites through domain names rather than memorizing IP addresses.
Let's go through an example. Thank you Codedamn for explaining this to me. Check out Codedamn for great content.
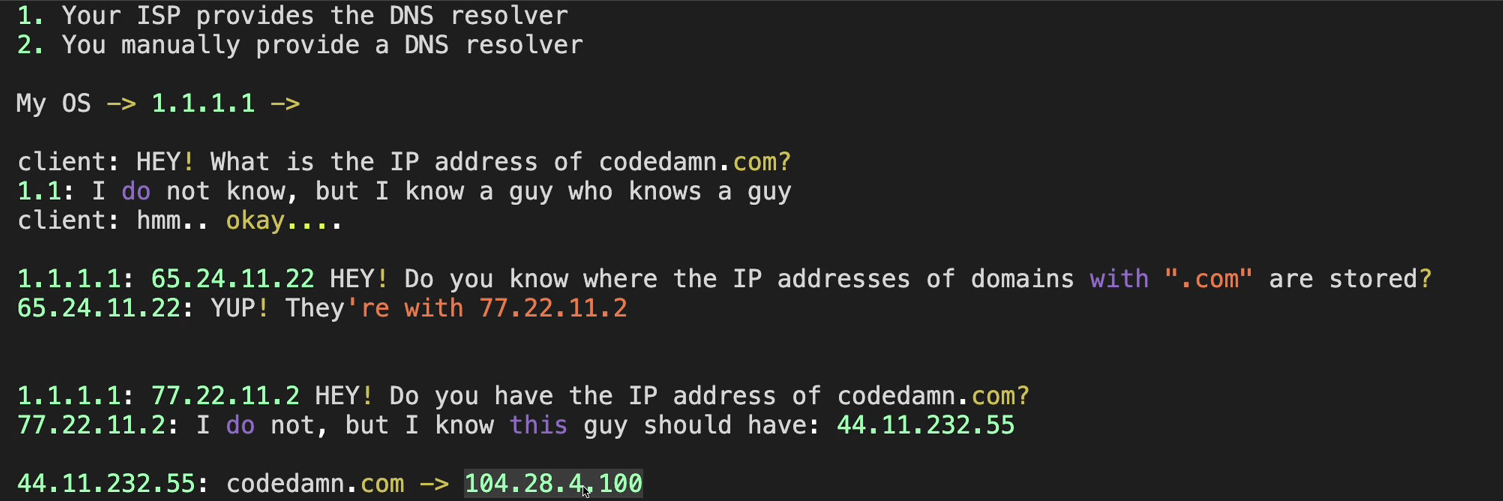
The steps followed are:
Our ISP already provides a DNS resolver or we do. It is a hard-coded IP address that maintains a kind-of look-up table for domains to their IP address.
On getting a request, our OS asks the DNS's IP what is the IP address of the website we are looking for. In this case "codedamn.com".
A request chain ensues where 1.1.1.1 (our IP) asks another server, for example, 65.24.11.22 where the IP address of all ".com" domains are stored. He replies with the required IP of the server. (77.22.11.2)
We do not get the IP of "codedamn.com" from 77.22.11.2. But it points us towards 44.11.232.55
We finally get the required IP from 77.22.11.2.
These domain-to-IP conversions are cached so that the entire request chain is not executed again.
Web Servers
Web servers are software programs that run on a server computer and handle HTTP requests and responses for web pages and web applications. When a user requests a web page or application from a web server, the server responds with the requested content, which is then displayed in the user's web browser.
Apache and Nginx are two of the most popular web servers in use today. Here's a brief overview of how they work:
Apache: Apache is an open-source web server that has been around since the mid-1990s. It uses a multi-process architecture where each incoming connection is handled by a separate process or thread. When a user makes an HTTP request, Apache receives the request and passes it to a worker process. The worker process then handles the request, generates the response, and sends it back to the user's web browser.
Apache is highly configurable and supports a wide range of modules that can be used to add functionality to the server. This makes it a popular choice for hosting dynamic websites and applications.
Nginx: Nginx (pronounced "engine-x") is a lightweight, high-performance web server that was created in 2004. It uses an event-driven, non-blocking architecture that allows it to handle a large number of simultaneous connections without using a lot of system resources. When a user makes an HTTP request, Nginx receives the request and passes it to a worker process or thread. The worker process then handles the request, generates the response, and sends it back to the user's web browser.
Nginx is often used as a reverse proxy, which means it sits in front of other web servers and distributes incoming requests to those servers. This can help improve the performance and scalability of a web application.
Both Apache and Nginx are powerful web servers with their own strengths and weaknesses. Choosing between them often depends on the specific needs of a website or application, as well as the preferences of the web administrator.
NOTE: You don't need to know about either of these servers to get into the backend development series. But basic knowledge is always a plus.
Sub-Net Masks
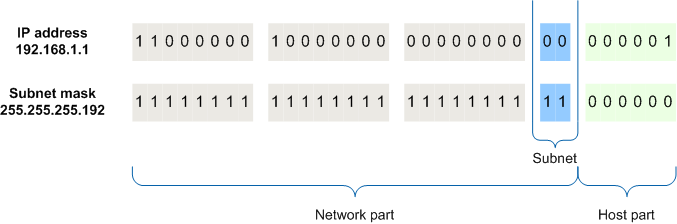
Subnet masks are a way of dividing a network into smaller subnetworks, or subnets. A subnet mask is a 32-bit binary number that is used to identify the network portion and the host portion of an IP address.
In IPv4, an IP address consists of 32 bits, divided into four 8-bit octets. Each octet represents a number between 0 and 255, and is separated by a period. For example, the IP address 192.168.0.1 is represented as 11000000.10101000.00000000.00000001 in binary.
A subnet mask is also a 32-bit binary number, where the network portion of the IP address is represented by a string of ones, and the host portion is represented by a string of zeros. For example, a subnet mask of 255.255.255.0 is represented as 11111111.11111111.11111111.00000000 in binary.
The subnet mask is used to determine which part of an IP address represents the network and which part represents the host. The network portion of an IP address is used to identify the network that the host belongs to, while the host portion is used to identify the individual host within the network.
By using subnet masks, a network can be divided into smaller subnets, each with its own network and host portion. This allows for more efficient use of IP addresses and can improve network performance and security.
In CIDR (Classless Inter-Domain Routing) notation, the subnet mask is specified by indicating the number of bits used for the network portion of the IP address. In the case of /25, which means that the first 25 bits of the IP address are used to identify the network portion, and the remaining 7 bits are used to identify the host portion.
For example, if a network has the IP address range 192.168.0.0/24 and a subnet mask of 255.255.255.0, it can be divided into smaller subnets with their own unique network portion and host portion. A subnet with the IP address range 192.168.0.0/25 would have a subnet mask of 255.255.255.128 and can support up to 126 hosts, while a subnet with the IP address range 192.168.0.128/25 would also have a subnet mask of 255.255.255.128.
Security Considerations
Security considerations are crucial when it comes to both servers and clients. There are several key measures that can be taken to ensure the security of these systems, including the use of Firewalls, SSL/TLS, and HTTPS.
In computing, a Firewall is a network security system that monitors and controls the incoming and outgoing network traffic based on predetermined security rules. A firewall typically establishes a barrier between a trusted network and an untrusted network, such as the Internet. At its most basic, a firewall is essentially the barrier that sits between a private internal network and the public Internet. A firewall’s main purpose is to allow non-threatening traffic in and to keep dangerous traffic out.
SSL/TLS is another important security measure that is commonly used in both servers and clients. SSL (Secure Sockets Layer) and its successor, TLS (Transport Layer Security), are cryptographic protocols that provide secure communication over the internet. SSL/TLS is commonly used to secure web traffic, email, and other types of online communications. SSL/TLS works by encrypting data transmitted between a server and a client, making it difficult for unauthorized users to intercept and read the data.
HTTPS is a secure version of the HTTP protocol used to transfer data over the internet. It uses SSL/TLS to encrypt the data transmitted between a server and a client, providing an additional layer of security to web traffic. HTTPS is commonly used to protect sensitive data, such as credit card numbers, passwords, and other personal information.
It is essential to keep these measures up to date and regularly review and update security protocols to maintain the highest level of protection.
Challenges in Scalability
Scalability is a crucial consideration for web servers that experience high levels of traffic. As web traffic increases, web servers may struggle to keep up with demand, which can lead to slow page load times, downtime, and other issues. There are several challenges that need to be addressed to achieve scalability in web servers, including load balancing, caching and clustering.
Load balancing is a technique that distributes incoming web traffic across multiple servers to avoid overloading any single server. Load balancing can be achieved through various methods, such as round-robin or weighted round-robin, IP hash, or least connections. Load balancing helps to ensure that incoming web traffic is evenly distributed among servers, reducing the load on any single server.
Caching is another technique that can be used to improve the scalability of web servers. Caching involves storing frequently accessed data in memory or on disk, which can significantly reduce the load on the server. Caching can be implemented at various levels, such as database caching, object caching, or page caching.
Clustering is a technique that involves grouping multiple servers together to act as a single system. Clustering can improve scalability by distributing the load among multiple servers, increasing the capacity of the system. Clustering also provides redundancy, which can help to ensure that the system remains available in the event of a server failure.
Load Balancing
Load balancing is the process of distributing workloads or traffic evenly across multiple resources, such as servers or network links, in order to optimize resource utilization, increase performance, and improve the availability and reliability of the system.
Load balancing is needed because as a system grows, it can become overwhelmed by requests or traffic, causing slowdowns or failures. By distributing the workload across multiple resources, load balancing ensures that no single resource becomes overwhelmed, thereby improving the overall performance and availability of the system.
Load balancing is helpful in many ways, including:
Scalability: Load balancing allows a system to scale out by adding more resources to handle increasing demand, rather than scaling up by adding more capacity to a single resource.
Fault tolerance: Load balancing ensures that if one resource fails, traffic can be automatically rerouted to another resource to avoid downtime or service interruption.
Performance: Load balancing can improve the performance of a system by evenly distributing traffic across multiple resources, which can help reduce response times and increase throughput.
There are different load-balancing algorithms that can be used to determine how traffic is distributed among resources. These include:
Round-robin: Traffic is distributed in a cyclical manner among the available resources.
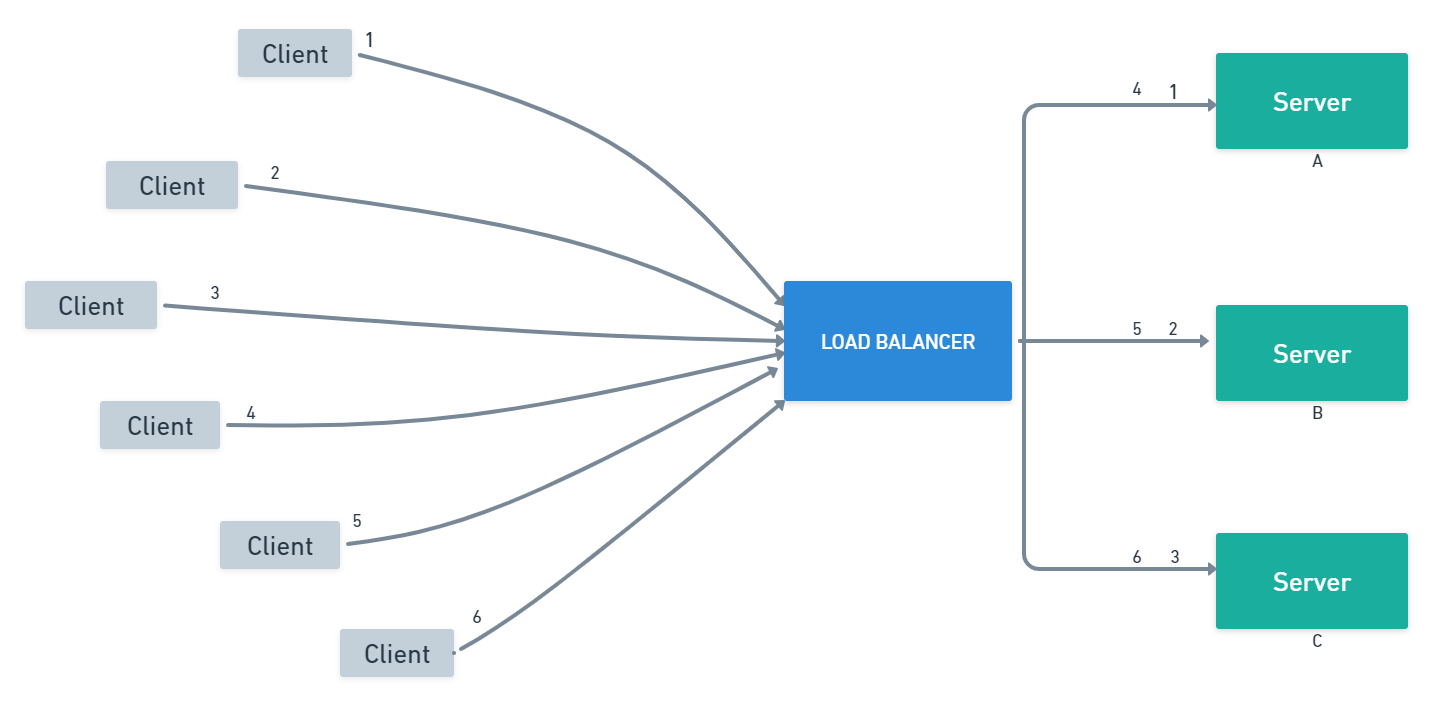
Least connections: Traffic is sent to the resource with the fewest active connections.
IP hash: Traffic is distributed based on the source or destination IP address.
Load balancing can be implemented at different layers of the network stack, including the application layer, transport layer, and network layer. Application-level load balancing involves distributing traffic based on application-specific criteria, such as HTTP headers or cookies. Transport-level load balancing involves distributing traffic based on transport-layer protocols, such as TCP or UDP. Network-level load balancing involves distributing traffic based on network-layer protocols, such as IP addresses or routing information.
Overall, load balancing is a key technique for improving the performance, availability, and scalability of modern computer systems, and it plays an important role in ensuring that critical applications and services remain available and responsive to users.
Content Delivery Networks (CDN)
A CDN (Content Delivery Network) is a system of distributed servers that deliver web content to users based on their geographic location. The goal of a CDN is to reduce latency, improve page load times, and increase the availability of web content.
When a user requests a piece of content, such as an image or video, the request is routed to the nearest CDN server, which is usually the one with the lowest latency or closest geographic proximity to the user. The CDN server then serves the content to the user, bypassing the need for the request to travel back to the origin server where the content is hosted.
CDNs can improve performance in several ways:
Reduced latency: By serving content from a nearby server, CDNs can reduce the time it takes for content to travel from the origin server to the user's device, reducing latency and improving page load times.
Improved availability: CDNs can help ensure that content is always available by replicating it across multiple servers. If one server fails or becomes overloaded, the request can be automatically routed to another server.
Reduced network congestion: By serving content from a nearby server, CDNs can reduce the amount of traffic that needs to travel over long distances, which can help reduce network congestion and improve overall network performance.
Caching: CDNs can cache frequently accessed content on edge servers, which can reduce the load on origin servers and improve page load times for subsequent requests.
Security: CDNs can provide security features such as DDoS protection and SSL encryption to help protect against attacks and improve the security of web content.
Overall, CDNs are an important tool for improving the performance and availability of web content, particularly for websites or applications with a global user base. By leveraging a distributed network of servers, CDNs can help reduce latency, improve availability, and enhance overall user experience.
That was most of the basics cleared out of the way before we move on to the backend dev blog. We have to touch on a few bits and bobs, which we will take care of in the next video. If you did find this helpful, stay tuned/like/all that good stuff. Will write on more topics. If you still have any questions/queries you can reach out to me on my LinkedIn / GitHub / Twitter.
Cheers!




