Introduction to MongoDB - Part 1

MongoDB is a popular NoSQL document database that stores data in flexible, JSON-like documents. Unlike traditional SQL databases, MongoDB does not require a predefined schema, making it easier to store and query data of varying types and structures.
One of the main reasons why MongoDB is a popular choice for backend development is its scalability. MongoDB is designed to scale horizontally by adding more servers to handle increased traffic and data volume, making it an ideal choice for large-scale, high-traffic applications. Additionally, MongoDB's flexible data model makes it easier to adapt to changing business needs, reducing development time and effort.
Another key advantage of MongoDB is its ease of use. With MongoDB, developers can write queries using a simple syntax similar to JSON, which is easier to learn and understand than SQL. Additionally, MongoDB's query language supports a wide range of operations and allows for complex queries, making it well-suited for data analytics and reporting.
Finally, MongoDB is highly versatile and can be used in a wide range of applications, including web and mobile applications, content management systems, and Internet of Things (IoT) devices. Its compatibility with popular programming languages and frameworks, including Node.js and the MERN stack, makes it a popular choice for modern web application development.
How is MongoDB different?
MongoDB is a popular NoSQL document-oriented database that stores data in a flexible, JSON-like format called BSON. Unlike traditional relational databases, MongoDB does not require a predefined schema or structure for data storage, making it easier to store and query data of varying types and structures.
Some of the key differences between MongoDB and relational databases/SQL databases include:
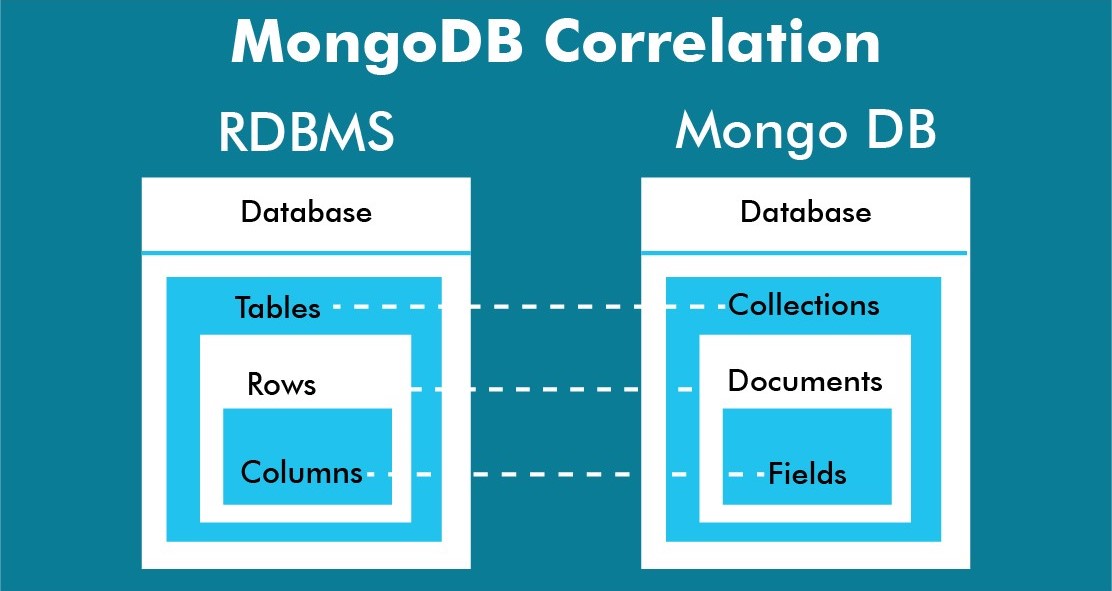
Data model: MongoDB uses a document-based data model, whereas SQL databases use a table-based model. In MongoDB, documents are stored in collections, which can contain different types of data, while SQL databases require data to be structured in tables with predefined columns.
Schema design: MongoDB does not require a predefined schema for data storage, whereas SQL databases require a schema to be defined in advance. This means that MongoDB can be more flexible when it comes to schema design, as changes can be made on-the-fly without affecting the overall database structure.
Query language: MongoDB uses a simple, JSON-like query language, whereas SQL databases use SQL (Structured Query Language), which is more complex and requires knowledge of database schemas and table structures.
Advantages of MongoDB:
Scalability: MongoDB is highly scalable and can easily handle large amounts of data and high levels of traffic by distributing data across multiple servers.
Flexibility: MongoDB's flexible data model allows for easier schema design and more efficient storage and querying of complex data structures.
Performance: MongoDB's indexing and sharding capabilities enable faster query times and efficient data retrieval.
Open source: MongoDB is an open-source platform with a large community of developers, making it easy to find support and resources.
Disadvantages of MongoDB:
Complexity: While MongoDB's flexible data model is an advantage, it can also be a disadvantage as it can be more complex to manage and query than a structured, relational database.
Memory usage: MongoDB requires more memory than traditional SQL databases, as it relies heavily on in-memory caching for performance.
Lack of transaction support: MongoDB does not support ACID transactions, which can make it more challenging to ensure data consistency and integrity in some use cases.
Terminologies
Some of the terminologies used in MongoDB are:
Database: A MongoDB database is a container for collections of documents. Each database can have multiple collections, and collections can have multiple documents.
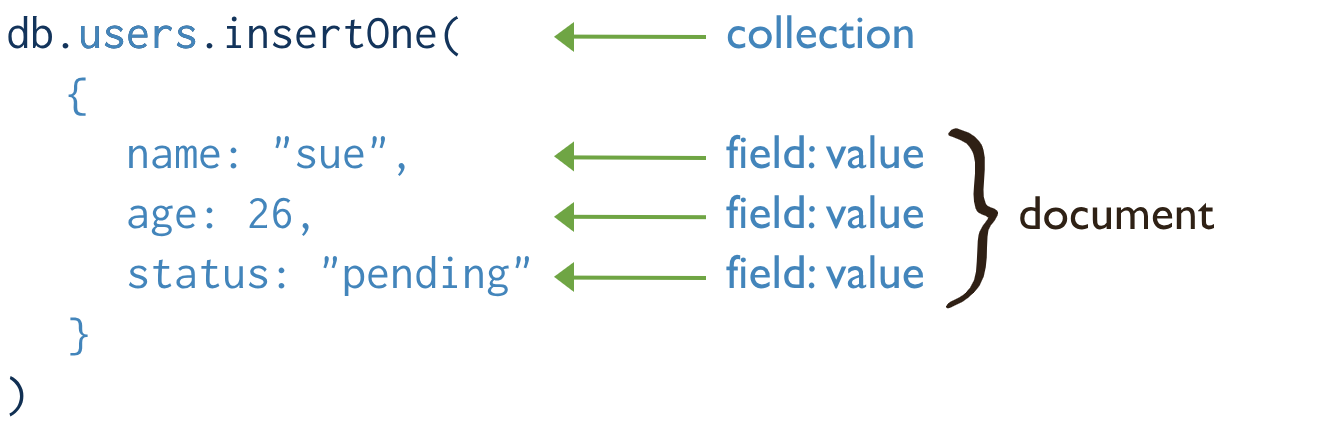
Collection: A MongoDB collection is a group of documents that share a similar structure. Collections are analogous to tables in a relational database, but they do not have a predefined schema or structure.
Document: In MongoDB, a document is a record stored in a collection. A document is represented as a JSON-style object and can contain fields of various data types.
Schema: A MongoDB schema defines the structure of documents within a collection, including the fields and data types for each field. Unlike a traditional database schema, MongoDB schemas are flexible and can be changed dynamically.
Model: In the context of Node.js and MongoDB, a model is a JavaScript object that represents a collection in MongoDB. A model provides an interface for querying and modifying documents in a collection.
Index: A MongoDB index is a data structure that improves the speed of data retrieval operations by allowing queries to quickly locate documents that match certain criteria.
Aggregation: MongoDB aggregation refers to the process of combining multiple documents from one or more collections to perform a set of data processing operations, such as filtering, sorting, and grouping.
These are some of the most commonly used terminologies in MongoDB, but there are many others as well.
How to design a Schema?
A schema is a blueprint that defines the structure of documents within a collection. Unlike traditional databases, MongoDB allows for flexible schemas, which means that documents within a collection can have different fields and data types.
Fields in MongoDB refer to the individual pieces of data stored within a document. A field consists of a name and a value. The name of a field is a string that identifies the data stored within it, and the value can be of any data type supported by MongoDB.
Types in MongoDB refer to the various data types that can be used to represent data within a field. Some common data types in MongoDB include:
String − This is the most commonly used datatype to store the data. The string in MongoDB must be UTF-8 valid.
Integer − This type is used to store a numerical value. Integer can be 32-bit or 64-bit depending upon your server.
Boolean − This type is used to store a boolean (true/ false) value.
Double − This type is used to store floating point values.
Min/ Max keys − This type is used to compare a value against the lowest and highest BSON elements.
Arrays − This type is used to store arrays or lists or multiple values into one key.
Timestamp − This can be handy for recording when a document has been modified or added.
Object − This datatype is used for embedded documents.
Null − This type is used to store a Null value.
Symbol − This datatype is used identically to a string; however, it’s generally reserved for languages that use a specific symbol type.
Date − This datatype is used to store the current date or time in UNIX time format. You can specify your own date time by creating an object of Date and passing a day, month, or year into it.
Object ID − This datatype is used to store the document’s ID.
Binary data − This datatype is used to store binary data.
Code − This type is used to store JavaScript code in the document.
Regular expression − This datatype is used to store regular expressions.
MongoDB also supports "pre" and "post" functions that allow developers to add custom functionality to document and query operations. "Pre" functions are executed before a specific operation, such as insert or update, and can be used to perform validations or transformations on the data being modified. "Post" functions are executed after a specific operation, such as insert or find, and can be used to perform additional processing on the result data.
These functions can be defined using MongoDB's built-in functions or custom JavaScript functions. They can be used to perform a wide variety of operations, such as data validation, transformation, logging, and more.
Querying and Manipulation
MongoDB offers powerful querying and aggregation capabilities, as well as support for indexing, to enable efficient and flexible data retrieval and manipulation.
Querying: MongoDB supports a wide range of query operators and methods for retrieving documents from collections based on specific criteria. Queries can be based on a single field, a combination of fields, or even nested fields within a document. MongoDB also supports a flexible query language that allows for complex logical expressions and regular expressions.
Aggregation: MongoDB's aggregation pipeline provides a flexible and powerful way to perform complex data transformations and analysis on collections. The pipeline consists of stages that can be used to filter, transform, group, and aggregate data in a variety of ways. Each stage in the pipeline takes input from the previous stage and passes the output to the next stage. This playlist by Bogdan Stashchuk has everything you need to get started working with MongoDB aggregation.
Indexing: MongoDB supports a wide range of indexing options to improve query performance and data retrieval times. Indexes can be created on single fields or combinations of fields within a collection. MongoDB supports several types of indexes, including unique indexes, text indexes, and geospatial indexes. Indexes can significantly improve query performance, especially for large collections, and can also support efficient sorting and range queries.
Scaling Techniques
Scaling MongoDB to handle larger datasets requires some or a combination of some techniques. They are:
Sharding: Sharding is a technique for horizontally scaling MongoDB across multiple servers. With sharding, data is distributed across multiple shards, which are groups of servers that each contain a subset of the data. Sharding can help to improve performance and handle larger datasets by allowing MongoDB to distribute the workload across multiple servers.
Replication: Replication is a technique for ensuring high availability and fault tolerance in MongoDB. With replication, multiple copies of the data are stored across multiple servers. Changes made to the data on one server are automatically replicated to the other servers in the replication set. This can help to improve performance and ensure that data is always available, even in the event of a server failure.
Indexing: Indexing is a technique for improving query performance by creating indexes on fields within a collection. Indexes allow MongoDB to retrieve and sort data efficiently, which can help to improve performance and reduce query times.
Compression: MongoDB supports several compression techniques that can be used to reduce the size of the data stored in the database. Compression can help to reduce storage requirements and improve performance, especially for larger datasets.
Caching: Caching is a technique for improving performance by storing frequently accessed data in memory. MongoDB supports several caching mechanisms, including the WiredTiger cache, which can help to improve performance and reduce query times.
Load balancing: Load balancing is a technique for distributing incoming traffic across multiple servers to improve performance and reduce the risk of overloading any individual server. Load balancing can help to improve performance and handle larger datasets by distributing the workload across multiple servers.
I hope this was an informative blog on MongoDB. There will be a second part that will build a much more practical understanding of MongoDB and its capabilities. If you did find this helpful, stay tuned/like/all that good stuff. Will write on more topics. If you still have any questions/queries you can reach out to me on my LinkedIn / GitHub / Twitter.
Cheers!




